Chapitre 10 : Le routage IP
Généralités
Problématiques du routage
Avant de commencer à établir la table de routage, il faut commencer par se poser les bonnes questions. Tous d’abord, il est interdit, lorsque l’on route, de faire des boucles. En effet, lorsque qu’un paquet sera pris dans une boucle il sera échangé entre les routeurs jusqu’à sa destruction (à la fin du TTL).
Lorsque l’on fait du routage, parfois plusieurs chemins permettent d’arriver au même endroit. Il faudra donc faire un choix, afin de choisir la meilleure route :
- Prendre celle qui traverse le moins de nœuds ;
- Calculer un “coût” en fonction de la vitesse entre les différents nœuds et choisir le coût le plus faible ;
On doit aussi réfléchir à la manière de remplir la table de routage. Deux choix s’offrent à nous : le routage statique où l’administrateur remplit la table à la main et le routage dynamique où la table de routage est remplie par un logiciel. Il existe différents protocoles de routage dynamique : OSPF, RIP, BGP… On choisira le protocole en fonction du réseau et du matériel choisit. Par exemple, RIP n’est pas adapté aux grands réseaux, on préfèrera OSPF. BGP est utilisé pour le routage Internet, il existe dans deux modes iBGP et eBGP…
Pendant le routage…
Le routage fait voyager les paquets de routeur en routeur. Au niveau des couches réseaux, le routeur ne modifie que les couches inférieures, et retransmet à l’identique les couches supérieures.
Ainsi, quand un routeur reçoit une trame, il la décapsule pour récupérer le paquet. Ensuite il va lire l’adresse du paquet et utiliser sa table de routage pour savoir sur quelle interface il va le transmettre. Ensuite, il encapsule le paquet et mettra l’adresse du routeur suivant dans la trame.
La table de routage
Nous avons vu dans la première partie que la table de routage devait connaître la destination de chaque hôte. Afin de raccourcir la table de routage, chaque entrée correspondra à un sous-réseau que nous avons vu dans le chapitre 7.
L’autre information contenue dans la table de routage est la passerelle (gateway). Une passerelle est une adresse IP désignant le prochain routeur à joindre ou l’interface réseau de sortie. On la choisira donc de cette façon :
- si le sous-réseau est directement joignable par le routeur, alors on mettra
0.0.0.0; - si le sous-réseau n’est pas directement joignable par le routeur, on devra alors passer par un autre routeur, il faudra donc mettre son IP. Dans ce cas, le routeur utilisé en passerelle devra obligatoirement être dans le même sous-réseau que le routeur.
La passerelle permettra au routeur de trouver l’interface de sortie. Voici un exemple de table de routage :
| Destination | Passerelle | Masque de sous-réseau | Interface |
|---|---|---|---|
192.168.0.0/24 |
0.0.0.0 |
255.255.255.0 |
eth0 |
192.168.1.0/24 |
0.0.0.0 |
255.255.255.0 |
eth1 |
192.168.2.0/24 |
192.168.1.2 |
255.255.255.0 |
eth1 |
192.168.3.0/24 |
192.168.0.3 |
255.255.255.0 |
eth0 |
Il existe une autre forme de route : les passerelles par défaut. En effet, cette passerelle sera utilisée par les routeurs lorsque la destination à joindre n’est pas dans la table de routage. On la représente en mettant l’adresse IP 0.0.0.0 dans destination. Voici un exemple de passerelle par défaut :
| Destination | Passerelle | Masque de sous-réseau | Interface |
|---|---|---|---|
0.0.0.0 |
192.168.1.1 |
0.0.0.0 |
eth0 |
Le routage statique consiste à remplir la table de routage à la main, cette technique est parfaite pour des petits réseaux, mais elle devient pénible voire ingérable pour des réseaux de taille plus importante. De plus, le routage statique n’offre aucune solution pour rediriger les paquets lors de la panne d’un routeur ou d’un câble coupé. Le routeur continue à diriger le flux vers la sortie désignée dans la table de routage sans tenir compte d’autres problèmes. Voyons maintenant les techniques utilisées dans le routage dynamique.
Les commandes
Sous un système d’exploitation Linux, on utilisera la commande route pour afficher la table de routage. Pour la modifier, il suffira d’ajouter des arguments, voici comment on ajoute une route vers le sous-réseau 192.168.1.20/255.255.255.0 en utilisant la passerelle 192.168.2.1 :
route add -net 192.168.1.0 netmask 255.255.255.0 gateway
192.168.2.1
Pour supprimer la route, il suffira de taper la même commande en remplaçant “add” par “del”.
Le routage dynamique
Le routage dynamique est une technique permettant de modifier la table de routage automatiquement. Cette modification est effectuée par un logiciel qui échangera des informations avec les autres routeurs en utilisant un protocole de routage dynamique. Tous les routeurs utilisant le même protocole s’échangeront des informations, il existe trois façons de faire cela :
- Vecteur de distance
- A chaque passage dans un routeur, un champ de la trame du message est incrémenté de un.
- État de liens
- Un lien est définit une interface réseau, un sous-réseau ou autre suivant les protocoles de routage. Des liens sont abondamment envoyés sur le réseau, tous les routeurs doivent connaître les mêmes liens. À partir de ces liens, on calcule la table de routage.
- Vecteur de chemin
- Se base sur les systèmes autonomes pour déterminer la route à suivre.
Nous avons vu au chapitre 3 ce qu’était les AS et la différence entre routage interne (IGP) et externe (EGP), voici une liste de protocole de routage :
| Nom | Utilisation | Algorithme |
|---|---|---|
| RIP | IGP | Vecteur distance |
| OSPF | IGP | État de liens |
| BGP | EGP et IGP | Vecteur de chemin |
| IS-IS | IGP | État de liens |
RIP
RIP est un protocole de routage IGP utilisé dans les réseaux de taille peu importante. Comme nous l’avons vu tout à l’heure, RIP est un protocole à vecteur de distance. Les informations de routage vont donc passer de routeur en routeur en incrémentant un champ de un à chaque changement de routeur. Lorsque RIP a le choix entre deux routes, il choisira celle qui passera par le moins de routeur.
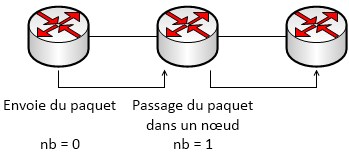
Ce protocole est toutefois moins performant qu’OSPF car il ne prend pas en compte le débit des différentes liaisons entre les routeurs. De plus, il n’est pas adapté aux grands réseaux.
Le protocole OSPF
OSPF signifie Open Shortest Path First, ce protocole utilise des liens afin de partager des informations de routage.
Base de données topologique
Il existe un vocabulaire particulier pour décrire OSPF, voici pour commencer deux définitions :
- Un lien
- Un lien permet de décrire une liaison entre deux routeurs, entre un routeur et un réseau…
- Base de données topologique
- Contient la liste des liens, elle va permettre à OSPF de construire la table de routage.
La base de données topologique d’OSPF contient en fait des Link-State Adevertissement (LSA). Il existe cinq types de LSA :
- Type 1 : Router LSA, décrit les différentes interfaces réseau d’un routeur ;
- Type 2 : Network LSA, contient la liste des routeurs connectés à un réseau ;
- Type 3 et 4 : Summary LSA générés par les routeurs de bordure, ils permettent d’échanger des informations de routage entre les aires ;
- Type 5 : AS-External LSA permet d’échanger des informations de routage entre deux systèmes autonomes.
Ce sont ces informations qui sont échangées dans les différents paquets qu’OSPF envoie. Ces paquets sont au nombre de cinq : HELLO, DATABASE DESCRIPTION, LSR, LSU, LSAck.
OSPF s’appuie sur la dissémination fiable des informations afin que tous les nœuds puissent créer leurs tables de routage. Pour cela OSPF utilise des acquittements pour être sûr que toutes les informations soient envoyées. Chaque nœuds ayant OSPF d’installé devront avoir une base de données topologique synchronisée.
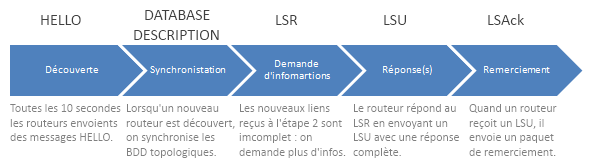
Voici quelques détails à propos de la figure présentée ci-dessus :
- Étape 1 : la découverte
- Les messages
HELLOpermettent de découvrir et de maintenir une liaison entre deux routeurs voisins. Afin de construire la base de données topologique, OSPF va envoyer des messagesHELLOà intervalle régulier sur l’adresse multicast224.0.0.5. Toutes les machines ayant OSPF d’installé vont recevoir ces messages. Ces messages sont envoyés à une période fixe, par défaut cette valeur est à dix secondes. Si un routeur n’envoie plus deHELLO, les routeurs voisins le détecteront et enverront desLSUpour transmettre cette information aux autres routeurs. Quand un routeur reçoit un messageHELLO, il va regarder si le routeur est déjà dans la base de données topologique. - Étape 2 : synchronisation
- Si ce routeur n’est pas dans la base de données topologique, il va l’ajouter puis envoyer un
DATABASE DESCRIPTION. Ces paquets permettent de synchroniser deux routeurs, en effet, lesDATABASE DESCRIPTIONcontiennent un nombre (appelé Sequence Number) qui est calculé en fonction de la base de données topologique. Si les deux nombres sont identiques, alors les bases de données topologiques sont synchronisées. Si les bases de données divergent, chaque routeur va envoyer un résumé de sa base de données. - Étape 3 : demandes des informations complètes
- Ensuite, les routeurs comparent le résumé avec leurs bases de données topologiques. Pour les nouveaux liens ou ceux obsolètes, il demandera plus d’information à l’autre routeur grâce au message
LSR(Link-State Request). - Étape 4 : réponse(s) contenant les informations
- Quand un routeur reçoit des
LSR, il va envoyer sur tout le réseau (en multicast) lesLSU(Link-State Update) correspondants. - Étape 5 : remerciement
- Une fois ces informations reçues, le routeur fait un Link-State Acknowledged, qui signifie “remerciement”, ce paquet est en fait un acquittement. Ce paquet est aussi envoyé sur tout le réseau.
Routeurs désignés
Les routeurs désignés serviront de référence dans le réseau. Il y aura un routeur primaire (DR) et un routeur secondaire (BDR). Il y a plusieurs avantages à cette architecture. En effet, cela permet de réduire le trafic lié à l’échange d’information sur les liens. De plus, cela permet d’améliorer l’intégrité de la table de routage et d’accélérer la convergence, autrement dit, la vitesse de calcul des routes.
On élira le DR en fonction du Router ID, celui qui aura le plus grand sera désigné. C’est un choix arbitraire, sachant que le Router ID est un identifiant unique, coder sur quatre octets, afin de nommer le routeur dans la base de donnée topologique.
Il est toutefois possible de privilégier un routeur, pour le forcer à devenir DR ou au contraire pour éviter qu’il le devienne. Pour cela, on utilise la valeur priority qui est comprise entre 0 et 255. Plus le nombre est grand, plus le routeur aura de chance d’être élut DR.
Les routes
Grâce à la base de données topologique, le routeur OSPF va pouvoir déterminer les routes les moins coûteuses. Pour cela, il va utiliser le coût qui se calcul de cette manière :
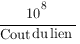
Par défaut, la valeur maximale du lien sera 108 bps soit 100 Mbps. Pour pouvoir utiliser des liens ayant plus de bande passante, par exemple du Gigabit, il faudra changer la valeur 108 par 109 sur chaque routeur du réseau.
Afin de déterminer la meilleure route, OSPF utilise un moyen de calcul simple : il additionne successivement les coûts de chaque lien, la route qui a le coût le plus faible sera le meilleur.
Les aires (area)
OSPF est un protocole pensé pour les réseaux de taille importante. Afin d’éviter d’utiliser toute la bande passante pour diffuser les routes, OSPF est capable de travailler avec plusieurs aires. Les aires regroupent un certain nombre de réseaux. Un routeur d’une aire ne connaît pas la topologie d’une autre aire sauf pour l’aire 0. En effet, cette aire est appelée “réseau fédérateur” ou backbone, elle est reliée physiquement à toutes les aires.
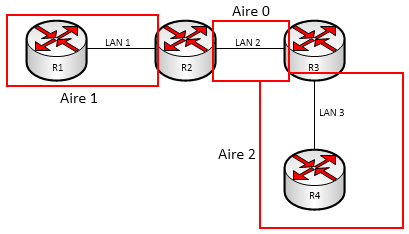
Pour déterminer les aires, il suffit de trouver un backbone, ici on prend R2 et R3. Ces deux routeurs sont des routeurs de bordure d’aires, “entre” ces deux routeurs, on aura donc le backbone (aire 0). Ensuite, il suffit de prendre chaque interface réseau des routeurs de bordure et de vérifier qu’elles ne soient pas dans l’aire 0.
BGP
Le protocole de routage BGP est utilisé sur Internet afin d’échanger les routes entre les différents FAI. BGP est un protocole EGP et IGP, appelé respectivement eBGP et iBGP.
Pour échanger des routes entre deux systèmes autonomes, on connecte deux routeurs, appartenant chacun à un AS (Système Autonome). On configure les deux routeurs afin qu’ils se reconnaissent en tant que voisin. Les deux routeurs vont s’échanger les routes déjà connues.
En fait, BGP créé une connexion TCP permanente avec le routeur voisin, cette connexion permettra d’échanger les informations de routage. Si la connexion TCP est rompue, le routeur sera considéré comme inactif, et le routeur va envoyer des messages à ces voisins, qui vont envoyer des messages à leur voisin, et de proche en proche tous les routeurs seront informés de la disparition du routeur. Un autre chemin devra donc être trouvé.
La NAT
La NAT (Network Translation Address) consiste à faire correspondre une IP à un sous-réseau. Cette technique est très utilisée chez les particuliers ou les réseaux Internet pour téléphone portable par exemple. En effet, une adresse IPv4 routable sur Internet a un certain coût, l’idée est donc de faire correspondre une seule de ces adresses à un sous-réseau qui peut contenir quelques machines à plusieurs centaines de machines.

La NAT utilise donc des adresses dites privées, que nous avons données précédemment et les adresses dites publiques ou routables sur Internet.
Pour envoyer des données, les utilisateurs envoient les données au NAT, la NAT changera l’adresse l’IP dans le paquet en mettant l’adresse IP publique comme adresse source. Il va stocker le port utilisé et l’associer à l’IP du sous-réseau.
Pour les données entrantes, l’utilisateur choisira d’ouvrir des ports. Ces-derniers pourront être redirigés seront redirigés vers une machine du sous-réseau. Les ports utilisés sont les mêmes que ceux utilisés avec TCP et UDP.