La virtualisation de machines
Après avoir parlé des conteneurs, j’ai décidé de parler de la virtualisation pour démystifier son fonctionnement. Je vous montrerai que cette solution est très intéressante malgré la complexité ajoutée par cette technique.
Présentation
De manière générale, on peut dire que la virtualisation est une technique permettant de créer des ressources virtuelles sur un système possédant des ressources physiques. Cela fonctionne pour des machines virtuelles, pour du stockage, pour des réseaux… La virtualisation permet de créer une interface entre des ressources physiques qui peuvent être très différentes et des ressources virtuelles. Les ressources virtuelles pourront accéder de manière simplifiée aux ressources physiques en utilisant cette interface sans avoir à connaître toute la complexité sous-jacente. Dans cet article, je me limiterai à la virtualisation des ordinateurs (ou serveurs).
Les ordinateurs
Un ordinateur est une machine possédant un certain nombre de ressources matérielles et logicielles permettant de faire fonctionner des programmes. Un ordinateur est construit en suivant une certaine architecture qui est normalisée afin de créer des composants standards. L’architecture la plus répandue dans l’informatique est le x86, une autre architecture faire également parler d’elle : l’architecture ARM.
Un ordinateur possède plusieurs types de ressources comme le processeur (CPU) qui permet d’exécuter les instructions des programmes, la mémoire vive (RAM) qui est une mémoire rapide permettant de sauvegarder temporairement des informations, la mémoire de masse (disque dur) permettant de stocker des informations et des programmes à plus long terme.
L’ordinateur fonctionne sous la forme de couches pouvant être matérialisées par des cercles appelés “rings”.
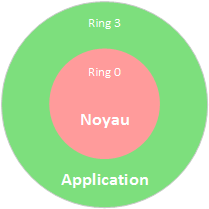
Il existe en réalité 4 rings, mais les deux autres n’étant pas très utilisés, j’ai préféré ne pas les représenter. Le ring 3 représente les applications que l’utilisateur va exécuter. Celles-ci n’ont pas directement accès au matériel physique de l’ordinateur et devront faire des appels au noyau (kernel) du système d’exploitation pour y accéder (qui se trouve au ring 0). Lorsqu’une application s’exécute, un processus naît, il est composé d’une suite d’instruction permettant de définir un programme à exécuter. Ces instructions seront exécutées par le processeur. Le noyau se chargera d’exécuter les instructions des processus tour à tour pour donner l’illusion que les processus peuvent s’exécuter en même temps.
Lors de l’exécution d’un programme, ses instructions sont placées en mémoire. Le système d’exploitation définit deux espaces mémoire en fonction des instructions à exécuter :
- l’espace noyau (kernel space) qui contiendra les instructions qui ont des privilèges “noyau”. C’est le niveau de privilège le plus élevé dans la machine (il correspond au ring 0) et permet d’accéder au matériel de la machine. Seul le noyau et les drivers exécutent des instructions avec ce niveau.
- l’espace utilisateur (user space) qui contiendra les instructions qui ont des privilèges “utilisateur”. Il possède un niveau de privilège moins élevé que le premier (il correspond au ring 3) et ne permet pas d’accéder au matériel de la machine. Ce niveau est utilisé essentiellement par les applications exécutées par l’utilisateur.
Techniques de virtualisation
Il existe plusieurs techniques pour faire de la virtualisation, ici je vais vous présenter les techniques permettant de faire fonctionner un système dit “invité” sur un système “hôte” qui l’accueillera. Ces techniques auront des utilisations différentes et des performances très différentes.
Un de ces techniques est l’émulation, elle vise à reproduire de manière logiciel le fonctionnement d’une solution matérielle ou d’un logiciel précis en simulant son comportement. Lorsque l’on va communiquer avec le logiciel d’émulation va agir comme si il était le matériel qu’il émule. On utilise cette technique quand on ne peut pas faire autrement car c’est la solution la moins performante.
La virtualisation de plateforme est une technique plus courante dans le monde de la virtualisation. Elle permet de faire une abstraction du matériel physique pour faire fonctionner un système d’exploitation. Ici on crée une machine virtuelle qui aura du matériel virtuel et celui-ci sera utilisé pour faire tourner un système d’exploitation invité. La différence principale avec l’émulation est qu’une machine virtuelle va avoir la même architecture matérielle que le système hôte. Elle pourra donc accéder directement au matériel physique, en vérifiant toutefois qu’elle n’impacte pas le reste de l’hôte ou les autres machines virtuelles. Cela augmente grandement les performances par rapport à l’émulation.
La virtualisation au niveau du système d’exploitation (Operating-system-level virtualization) permet non pas de faire fonctionner un système d’exploitation complet mais de faire tourner des processus isolés du reste du système. L’isolation est réalisée au niveau du noyau du système d’exploitation hôte. Dans ce cas, on ne parle pas de machines virtuelles mais de conteneurs que j’ai déjà présentés dans un article précédent.
Dans la suite de cet article, je ne parlerai plus que de la virtualisation de plateforme.
Utilisation
La première utilisation de la virtualisation qui nous vient à l’esprit est la possibilité de faire fonctionner plusieurs machines virtuelles sur une seule machine physique. Le bénéfice de cette solution est avant tout économique : on obtient un gain de place et on consomme moins d’énergie à avoir une seule grosse machine que d’avoir plein de petites.
Mais la virtualisation c’est aussi un gain en flexibilité. Une entreprise aura la possibilité de créer, en quelques clics, une nouvelle machine en quelques minutes qui aura un système d’exploitation déjà installé. Avec la création d’un cluster, il est possible d’agréger plusieurs serveurs de virtualisation pour les faire travailler ensemble. Cette possibilité va vous permettre d’un côté de créer des machines virtuelles et de l’autre, lorsque vous n’avez plus assez de ressources, d’ajouter de nouvelles machines physiques. Les ressources physiques seront donc devenues complètement abstraites.
Tous les serveurs de virtualisation (à condition qu’ils soient compatibles entre eux) pourront accueillir vos machines virtuelles. Une machine virtuelle ne dépendra plus d’un serveur et pourra même être déplacer d’un serveur à l’autre. D’autres fonctionnalités plus avancées ont été créé afin d’améliorer la disponibilité des machines virtuelles. D’abord la “haute disponibilité” (HA) des machines virtuelles : en cas de panne d’un hôte, elle offre la possibilité de redémarrer ses machines virtuelles sur un ou plusieurs autres hôtes en quelques minutes. Dans le même esprit, la “tolérance de panne” (FT) permet de faire synchroniser une machines virtuelles sur un deuxième hôte. Si le premier tombe en panne, le second reprend la main et la machine virtuelle n’arrête jamais de fonctionner. Attention, ces fonctionnalités ne sont pas disponibles sur toutes les plateformes de virtualisation.
Les hyperviseurs
L’hyperviseur est le programme utilisé pour faire fonctionner des machines virtuelles. L’hyperviseur peut être nommé “VMM” dans certaines documentations, mais les deux termes désignent la même chose.
Différents types d’hyperviseurs
Les hyperviseurs sont classés en deux catégories en fonction de leur manière d’accéder au matériel physique. Il est intéressant de savoir comment l’hyperviseur accède au matériel car cela conditionne fortement l’efficacité de votre solution de virtualisation.
L’hyperviseur de type 1, aussi appelé bare metal, possède un accès direct au matériel physique de la machine hôte. Pour ce faire, l’hyperviseur est directement installé sur le matériel en utilisant un système d’exploitation spécialisé. Le système d’exploitation et l’hyperviseur ne forment plus qu’une seule entité optimisée pour la virtualisation. Notons qu’un hyperviseur de type 1 peut également être conçu pour fonctionner sur un système d’exploitation généraliste. C’est le cas de KVM (Kernel-based Virtual Machine) qui est un hyperviseur fonctionnant sous Linux. Grâce à un module dans le noyau (kvm.ko), les capacités de Linux seront étendues et KVM aura la possibilité d’avoir accès directement au matériel physique grâce au noyau. Il existe d’autres hyperviseurs de type 1 comme Citrix XenServer, VMware ESXi et Microsoft HyperV.
L’hyperviseur de type 2, à l’inverse du premier, fonctionne à l’aide du système d’exploitation hôte comme n’importe quel autre programme. Dans ce cas, les ressources sont allouées à l’hyperviseur par le système d’exploitation et n’a pas directement accès au matériel. L’avantage de ce type de solution est que l’hyperviseur peut s’installer sur n’importe quelle machine et ne nécessite pas de privilège administrateur (ou root) pour créer des machines virtuelles. Cette catégorie regroupe les hyperviseurs utilisés sur des machines utilisateurs comme VirtualBox et VMware Player.
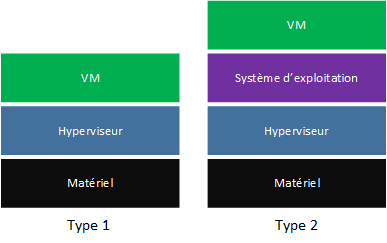
Attention toutefois, il n’y a pas de définition formelle de ces deux types d’hyperviseurs et la limite entre les deux est assez mal définie. Toutefois, il est assez important de comprendre comment les hyperviseurs accèdent au matériel car c’est ce qu’il les rendra plus ou moins performant.
Le matériel virtuel
Le système d’exploitation de la machine virtuelle interagit avec du matériel virtuel qui est créé par l’hyperviseur. Ce matériel est composé des différents organes présenté plus haut tel que le processeur et la mémoire vive. Le matériel virtuel inclut également les autres périphériques comme la mémoire de masse, la carte réseau, la carte graphique… Cette partie présentera les différentes techniques utilisées par l’hyperviseur pour gérer ce matériel virtuel.
Virtualisation du processeur
L’enjeu de la virtualisation est de permettre au système d’exploitation invité d’exécuter le maximum d’instructions sur le processeur de la machine hôte, car c’est le composant le plus rapide. Toutefois, le principe d’isolation de la virtualisation implique qu’une machine virtuelle n’agisse pas sur le matériel de l’hôte ni sur les autres machines virtuelles. Cette partie présentera les différentes techniques utilisées pour maintenir une isolation tout en optimisant les performances.
Virtualisation complète du processeur
La virtualisation complète du processeur combine deux techniques : la traduction des instructions (binary translation) et l’exécution directe (direct execution). Ces techniques sont utilisées en fonction du niveau de privilège de l’instruction que la machine virtuelle voudra exécuter.
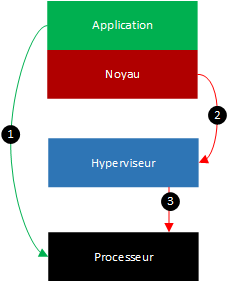
Si la machine virtuelle demande à exécuter une instruction avec des privilèges utilisateurs alors celle-ci n’aura pas d’influence sur le matériel de l’hôte : elle est sans danger. L’instruction sera alors exécutée directement sur le processeur : cette méthode est appelée l’exécution directe (flèche 1 du schéma).
Si au contraire, l’instruction nécessite d’être exécutée avec des privilèges noyau, celle-ci ne pourra pas être exécutée directement sur le processeur de l’hôte car l’instruction agira sur le matériel physique de l’hôte. L’hyperviseur sera capable de détecter ce genre d’instruction et les traduira en une suite d’instructions qui n’agiront plus sur la machine physique mais sur le matériel virtuel. C’est la technique dîtes de la “traduction des instructions” (flèche 2 et 3).
Avec la virtualisation complète du processeur, le système d’exploitation invité ne sait pas qu’il est virtualisé et n’a pas non plus besoin d’être modifié pour fonctionner dans une machine virtuelle.
Virtualisation assistée par le matériel
Avec la virtualisation assistée par le matériel, on utilisera des fonctionnalités propres au processeur physique pour réaliser la détection des instructions pouvant affecter le matériel physique. Ce travail n’est donc plus à faire par l’hyperviseur qui aura juste besoin de dire au processeur que des instructions provenant de machines virtuelles vont être exécutées. Cette fonctionnalité est disponible sur la plupart des processeurs, elle est appelée VT-x sur les processeurs Intel et AMD-V pour les processeurs AMD.
L’aide à la virtualisation d’Intel (et qui est assez similaire chez AMD) définit au sein du processeur deux modes d’exécution des instructions :
- Le mode root : dans ce mode, le processeur fonctionne de la même manière qu’un processeur sans VT-x. Il n’y a pas de restriction au niveau des privilèges des instructions exécutées. Le système d’exploitation hôte et ses programmes sont exécutés dans ce mode, c’est également le cas de l’hyperviseur.
- Le mode non-root : ce mode est différent du premier et s’adresse uniquement aux machines virtuelles. Les instructions n’ont pas tous les privilèges et sont validées avant d’être exécutée ou non par une structure interne au processeur nommée VMCS (Virtual Machine Control Structure). Son rôle est de déterminer ce que vont faire les instructions reçues pour savoir si elles peuvent être exécutées directement sur le processeur ou non.
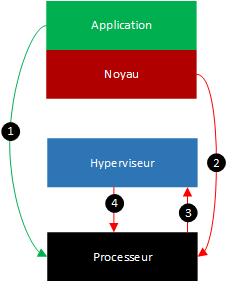
La machine virtuelle enverra toujours toutes ses instructions au processeur (flèche 1 et 2). Si une instruction agissant sur le matériel est détectée par le VMCS, un message “VM exit” sera envoyé à l’hyperviseur pour lui dire que l’instruction n’a pas pu être exécutée (flèche n°3). L’hyperviseur pourra alors exécuter lui-même l’instruction en la modifiant pour qu’elle n’affecte plus l’hôte mais uniquement la machine virtuelle concernée (flèche n°4).
La paravirtualisation du processeur
La paravirtualisation est très différente des deux techniques présentées précédemment. En effet, ce mode de virtualisation nécessite un système d’exploitation modifié pour supporter la paravirtualisation.
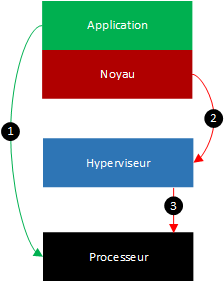
Les instructions avec des privilèges utilisateur sont toujours exécutées directement sur le processeur de la machine hôte car elles n’agissent pas sur le matériel (flèche n°1). Par contre, le noyau du système invité a été modifié pour que ses instructions demandant des privilèges plus élevés ne soient plus envoyées au processeur mais directement à l’hyperviseur grâce à des hypercalls (flèches 2). L’hyperviseur devra interpréter les hypercalls et exécuter les actions pour qu’elles agissent directement sur le matériel.
La principale différence entre la paravirtualisation et la virtualisation complète est le cheminement des instructions envoyées au processeur. Avec la paravirtualisation, le système invité envoie des requêtes à l’hyperviseur pour agir sur le matériel virtuel. Dans l’autre cas, l’hyperviseur devra intercepter les requêtes agissant sur le matériel, les modifier puis les envoyer au processeur.
Virtualisation de la mémoire
Lorsqu’un processus démarre sur un système d’exploitation classique, le système va lui attribuer de la mémoire virtuelle prélevée dans la mémoire physique. Une mémoire est un élément possédant des cases mémoires qui sont adressées. La mémoire virtuelle présentée au processus possède un plan d’adressage commençant à “0” pour que le processus n’ait pas à se soucier de savoir dans quelle case mémoire sont situées ses données. De plus, la mémoire virtuelle est adressée de manière continue, il n’y a pas de saut dans l’adressage des cases. Or dans la mémoire physique, ce n’est pas toujours possible de créer un espace mémoire en créant un seul morceau que l’on attribuera à un processus. La mémoire virtuelle permettra alors de masquer complètement cette complexité au processus. Les cases de la mémoire virtuelle sont adressées avec des cases de la mémoire physique grâce au MMU (Memory Management Unit).
Ce procédé sera toujours utilisé par le système hôte, sauf qu’il n’aura pas accès directement à toute la mémoire physique. On va donc attribuer à chaque machine virtuelle de la mémoire “virtualisée” (différente de la mémoire virtuelle expliquée précédemment) qui jouera le rôle de mémoire physique pour la machine virtuelle. La mémoire virtualisée sera associée à de la mémoire physique grâce à un composant faisant partie de l’hyperviseur appelé “MMU virtualisée”. Pour résumer, on trouvera trois plan d’adressages : la mémoire physique qui sera découpé en plusieurs espaces de mémoire virtualisée grâce à la MMU virtualisée. La mémoire virtualisée sera visible comme de la mémoire physique au sein de la machine virtuelle, elle sera donc à son tour découpée en plusieurs espace de mémoire virtuelle pour l’attribuer à chaque processus.
La MMU (non virtualisé) était un composant logiciel intégré au système d’exploitation. Elle a été déplacée directement dans le processeur pour améliorer sont efficacité. La MMU virtualisée est un composant logiciel faisant partie de l’hyperviseur. Toutefois, la nouvelle génération d’aide à la virtualisation permet au processeur de gérer également la MMU virtualisée en maintenant la table d’adressage directement dans le processeur. Cette technologie est appelée Intel EPT ou AMD NPT en fonction de la marque de votre processeur.
Virtualisation des autres périphériques
Les autres périphériques sont également présents sous la forme de matériel virtuel comme le disque dur, la carte graphique, la carte réseau… Ici aussi, il existe différentes méthodes pour virtualiser les périphériques :
- Emulation : on émule un matériel existant de manière complètement logiciel. En général, le système d’exploitation invité n’aura pas besoin d’installer le driver car les périphériques émulés sont très répandu et sont inclus dans le système d’exploitation.
- Paravirtualisation : cette méthode ressemble à la paravirtualisation du système d’exploitation. La machine virtuelle voit un périphérique ajouté par l’hyperviseur, et nécessite un driver spécial. Ce driver permet à la machine virtuelle de communiquer directement avec l’hyperviseur. Celui-ci peut également faire partie du système d’exploitation invité, comme c’est le cas avec “virtio”. virtio est une technologie open source de matériel et de driver paravirtualisé. Elle est présente nativement dans le noyau Linux et elle est exploitée par KVM.
- Passthrough : ce mode un peu spécial permet à la machine virtuelle d’accéder directement un périphérique physique.
Toutes les méthodes présentées ici ne sont pas disponibles pour tous les périphériques. De même, chaque hyperviseur n’implémente pas toutes ses techniques et il faut vérifier pour chaque périphérique son mode de fonctionnement.
Conclusion
Malgré la couche de complexité qu’elle ajoute, la virtualisation apporte beaucoup de flexibilité dans la manière de gérer son matériel informatique. Cette présentation est très théorique mais permet de mieux comprendre comment fonctionne un hyperviseur. En connaissant l’architecture d’un hyperviseur, on peut se faire une idée sur les performances que l’on peut attendre d’une solution de virtualisation. Ce qui faut retenir est qu’en général, une solution matérielle sera meilleure que son implémentation logicielle. Ainsi qu’une solution de paravirtualisation sera plus performante qu’une émulation ou une virtualisation totale. Cela permet de choisir la meilleure solution pour un périphérique ou pour choisir votre hyperviseur.
Bien que l’hyperviseur soit le composant essentiel à la virtualisation, il existe d’autres composants très important pour apporter de la flexibilité à une infrastructure informatique. C’est le cas par exemple des clusters que je vous ai présenté. J’aurais également pu vous parler de la virtualisation du stockage ou du réseau qui sont deux composantes essentielles dans la création d’une plateforme de virtualisation en entreprise.