Les clusters
Un cluster est un ensemble de plusieurs serveurs installés en réseau. Ces serveurs peuvent soit faire de la répartition de charge, soit partager des ressources telles que le CPU ou encore augmenter la disponibilité d’un service. Dans cet article, je parlerai de la haute disponibilité avec le heartbeat, puis du load balancing pour la répartition de charge.
Les explications seront théoriques ; pour savoir comment mettre en place ces systèmes, vous pouvez consulter l’article Mettre en place un cluster sous Linux.
Haute disponibilité

Il y a plusieurs manières d’organiser son réseau de serveurs. À chaque fois, nous isolerons un service et regarderons de quelles ressources il est dépendant pour fonctionner normalement. Commençons par un exemple : un site Internet classique utilisera l’architecture très classique LAMP (Linux Apache MySQL PHP). Ensuite, suivant l’importance de son site, il va utiliser un nombre n de serveurs. Il aura le choix entre :
- utiliser un serveur sur lequel tourneront Apache, PHP et MySQL (c’est ce qu’il y avait avant, donc ça ne change rien) ;
- utiliser un serveur sur lequel tourneront Apache et PHP, et un autre serveur sur lequel tournera MySQL ;
- d’autres fantaisies que je détaillerai peut-être dans l’article.
La véritable différence entre les deux premiers, c’est que le deuxième exemple sera plus performant. Dans les deux cas, si un serveur tombe en panne, le site est inaccessible.
Pour rendre un système hautement disponible, on regardera chaque point du cluster. Dans le cas d’un serveur, par exemple, on simulera une panne matérielle ou un plantage complet au niveau logiciel. Si le service s’arrête de fonctionner, on dira que le serveur était un single point of failure. Si le cluster ne possède pas ce problème, il sera lors redondant, il aura donc une tolérance de panne.
Heartbeat
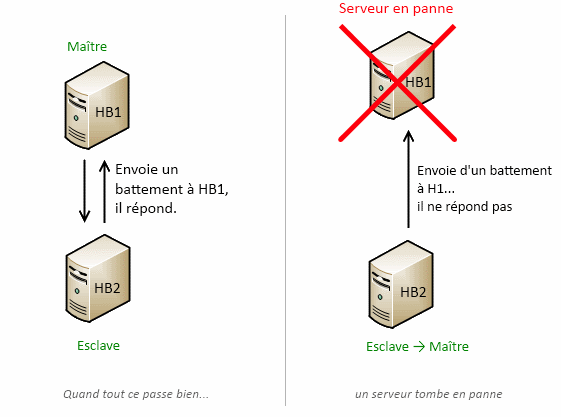
Le terme « heartbeat » signifie le “battement de cœur”. En effet, une machine “HB2” enverra un “battement de cœur” à une machine “HB1”. Ensuite, il peut se produire deux choses :
- “HB2” répond, cela veut dire qu’il fonctionne, ou plutôt qu’il est capable de répondre ;
- “HB2” ne répond pas, le serveur est donc éteint, ou déconnecté d’Internet… enfin peu importe, il ne peut pas répondre, il est considéré comme “mort”.
En fait, ce protocole ne se construit pas au hasard ; il y a toujours un serveur qui demande (“HB2”) et un autre qui doit répondre (“HB1”). “HB1” est donc le serveur maître, c’est ce serveur qui traitera les requêtes HTTP qui lui seront envoyées. À l’inverse, l’autre serveur est dit “esclave”. Lorsque tout fonctionne, ce n’est qu’un simple jeu de question / réponse. Mais quand le maître ne répond pas, l’esclave devient maître et exécute des commandes. Il existe plusieurs types de commandes, la seule qui nous intéresse est celle de l’IP.
Lorsque l’on créé un cluster, on va lui attribuer une adresse IP, par laquelle on accédera au service fourni : pour le serveur Web, c’est l’adresse qui permettra d’afficher le site. L’adresse IP du cluster est virtuelle, c’est donc elle que l’on va utiliser dans la commande. La commande peut être lue de deux façons :
- Le serveur passe du statut d’esclave à maître : la commande permettra d’ajouter une adresse IP, ici celle du cluster ;
- Le serveur passe du statut de maître à esclave : la commande permettra d’enlever l’adresse IP.
Par contre, lorsqu’un serveur en panne revient dans le cluster, il peut soit devenir maître, soit esclave suivant la configuration du cluster.
Conclusion : l’IP virtuelle passera d’un serveur à l’autre et le serveur Web sera toujours accessible, et aura une tolérance de panne d’un serveur HTTP. En effet, si un serveur tombe en panne, le service fonctionne ; si deux serveurs tombent en panne, il n’y a plus rien.
Problème de ce système
Ce système n’est pas vraiment utilisable dans le cas de notre LAMP tout simple, mis à part si l’on utilise un système de synchronisation de MySQL et des fichiers pour que les deux serveurs affichent le même contenu. Mais si vous faites un système MySQL indépendant, il constituera un single point of failure, c’est-à-dire qu’il suffira d’une panne du serveur MySQL pour que le site soit inaccessible.
Load balancing
Dans la famille des clusters, il y a aussi la répartition de charge (de l’anglais load balancing). C’est une technique simple pour augmenter la puissance de votre cluster. Par exemple, si votre serveur web sur lequel est installé Apache souffre d’un nombre de visiteurs important, vous pouvez l’appuyer grâce à un second serveur Apache, voire un troisième… le nombre est illimité. Les hébergements mutualisés d’OVH reposent sur un cluster de 5000 serveurs HTTP !
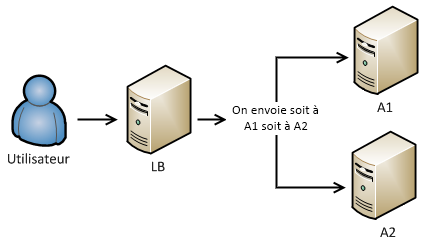
Pour faire un load balancing, vous avez besoin de N + 1 éléments, N représentant le nombre de serveurs. En effet, il est obligatoire dans un load balancing d’avoir une machine dédiée à la répartition de charge, qui se nomme load balancer. Cette machine peut être un serveur classique ou un routeur.
Algorithmes
Quel que soit la technique utilisée pour la répartition de charge, le load balancer devra choisir vers quelle machine diriger la requête. Il dispose toujours d’une liste de VM avec leur IP, mais il y a plusieurs techniques différentes pour choisir le serveur :
- Round Robin : il sélectionne un serveur au hasard ;
- Weighted Round Robin : il sélectionne un serveur au hasard mais en tenant compte d’un poids. On met un poids fort sur des serveurs plus puissant. Ils seront privilégiés dans le choix du serveur ;
- Least Connections : il sélectionne le serveur qui a le moins de connexions.
Utilisation d’un serveur DNS
Cette technique est un peu spéciale. En effet, je vous le rappelle, un DNS permet d’associer un nom textuel à une adresse IP. Ainsi, pour un nom “lightcode.fr”, je vais lui associer une IP : on utilisera pour cela un champ “A” :
@ A 127.0.0.1
Le “@” signifie bien “lightcode.fr”, on peut aussi rajouter, “www.lightcode.fr” :
@ A 127.0.0.1
www A 127.0.0.1
Chacune de ces lignes est appelée “champs”. Pour faire une répartition de charge, une astuce consiste à mettre deux champs “A” avec deux IP différentes sur un même nom. Le visiteur, en utilisant l’adresse arrivera soit sur le premier serveur, soit sur le deuxième, un petit exemple :
@ A 192.168.1.2
@ A 192.168.1.3
Le défaut de cette technique est qu’il n’est pas possible de mettre de sécurité : si un serveur tombe en panne, le visiteur pourra toujours être redirigé vers celui-ci. Le problème est le même en cas de surcharge.
Avec un logiciel dédié
Une autre technique consiste à utiliser un logiciel dédié à cette tâche, qui sera plus souple que le serveur DNS. Il existe différents types de configuration, en voici deux :
NAT
Le load balancer et les serveurs réels sont dans réseaux différents. Les connexions passent par le load balancer et sont redirigées vers les serveurs grâce au NAT (translation de port). Le NAT permet de passer d’un réseau à un autre en redirigeant les ports.
Exemple : le NAT a toujours une adresse située dans un autre réseau, votre boîtier ADSL possède une adresse dans le WAN (réseau Internet public) qui sera appelée “adresse IP publique”. Votre boîtier pourra être configuré pour rediriger le port 80 (Web) vers le port 80 d’une autre machine de votre réseau dit “local”.
Dans le cas d’une répartition de charge, c’est le même principe, bien que je doute de la faisabilité via un boitier ADSL classique. Les serveurs réels sont dans un réseau et n’ont pas d’accès vers l’autre réseau. Dans cet autre réseau, il y aura l’IP du cluster, ce n’est pas là qu’on accédera au site. Ensuite, lors de la configuration, on demandera à rediriger le port 80 de l’extérieur sur les deux IP des serveurs. Ainsi, lorsque que l’on visitera l’IP du cluster, on sera tantôt redirigé vers le premier serveur, tantôt vers le second.
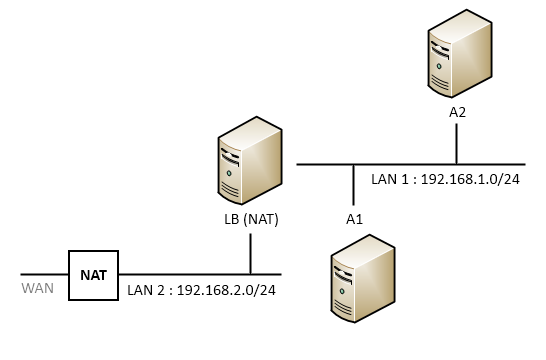
L’avantage de cette méthode est qu’elle permet d’utiliser n’importe quels OS pour le serveur réel.
Direct routing
Dans un direct routing, tous les serveurs se trouvent au sein d’un même réseau. Cette méthode est plus sûre et plus robuste que le NAT en cas de forts trafics.
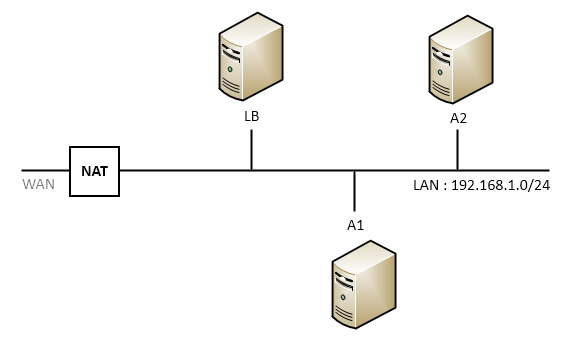
J’explique cette méthode dans l’article sur la mise en place des clusters.
Sortir les serveurs en panne d’un load balancing
Le problème soulevé par le load balancing est que, si vous ne faites rien, si un serveur tombe en panne, et bien le visiteur sera redirigé soit vers le serveur en panne, soit vers celui qui fonctionne. En effet, le load balancer ignore qu’un serveur est en panne vu que la liste d’IP est fixe et écrite lors de la configuration. Pour pallier ce problème, on utilisera un programme qui met à jour cette liste en permanence : à la manière d’un heartbeat, le programme enverra un signal aux machines ; si une machine ne répond pas, alors elle est supprimée de la liste.
Faiblesse du système
Le problème de ce système est qu’il faut synchroniser les fichiers pour ne pas que les deux serveurs affichent un contenu différent. Pour avoir des fichiers à jour sur tous les serveurs, on utilise un filer (ou serveur de fichiers), sur lequel on mettra tous les fichiers du site Web par exemple. Et comme pour le serveur MySQL, on crée un single point of failure ; il suffit que le serveur de fichier tombe en panne pour que tout le service soit en panne.
Évidemment, si le load balancer tombe en panne, le service est mort, même s’il y a 200 serveurs derrière. Pour ce type d’infrastructures, on doublera le load balancer en heartbeat comme je l’explique dans la partie suivante.
Combo de clusters
Je garde le meilleur pour la fin : utiliser deux clusters pour un site Web. On a vu le heartbeat qui nécessite deux serveurs, mais aussi le load balancing. Le problème de cette dernière technique est que si le load balancer tombe en panne, le service devient inaccessible. Mais si on met deux load balancer en heartbeat, on obtient un service totalement redondant.
Conclusion
Nous avons donc vu comment mettre en place un heartbeat et un load balancing simplement. Si vous êtes intéressé par la haute disponibilité et que vous voulez la tester, si vous n’avez pas le bon nombre de serveur réel ni les moyen de vous en payer, je vous conseille de faire de la virtualisation.
L’autre problème non résolu est que si le serveur MySQL ou le filer tombe en panne, le service ne fonctionne plus normalement ; pour éliminer tout single point of failure, le principe serait de faire un filer et un serveur MySQL redondants grâce au heartbeat.
Après, comme je commençais à le suggérer dans l’introduction, on ne mettra pas en place un tel service sur un petit site. Toutefois, on pourrait avoir, pour un site déjà important, un système de ce type :
- Un serveur DNS qui sert aussi de load balancer ;
- Deux ou n serveurs HTTP (Apache + PHP par exemple) ;
- Un serveur MySQL ;
- Un serveur de mail (mais on ne s’en occupe pas ici).
C’est l’architecture proposée par Gandi pour le site Millenium. Les fichiers sont hébergés sur les deux serveurs HTTP, ils sont envoyés sur les deux serveurs HTTP en même temps.